UNIX sort command sort a very large file?
- Published in CentOS 6
- June 18, 2013
The UNIX sort command can sort a very large file like this:
cat large_file|sort------------------------------------------------
The UNIX sort command can sort a very large file like this:
cat large_file|sort------------------------------------------------
今天在用yum升级一台新机器时,顾客用ssh远程把server重新启动了。之后,在使用yum 时总是有提示信息:
There are unfinished transactions remaining. You might consider running yum-complete-transaction first to finish them.
The program yum-complete-transaction is found in the yum-utils package.
意思是,有未完成的yum事务,建议先运行yum-complete-transaction命令清除。
处理步骤:
# 安装 yum-complete-transaction
yum install yum-utils
# 运行 yum-complete-transaction
yum-complete-transaction –cleanup-only
# 清除可能存在的重复包
package-cleanup –dupes
# 清除可能存在的损坏包
package-cleanup –problems
有个文件要处理,因为很大,所以想把它切成若干份,每份N行,以便并行处理。怎么搞呢?查了下强大的shell,果然有现成的工具--split。
下面记录下基本用法:
参数说明:
-b, --bytes=SIZE:对file进行切分,每个小文件大小为SIZE。可以指定单位b,k,m。
-l, --lines=NUMBER:对file进行切分,每个文件有NUMBER行。
prefix:分割后产生的文件名前缀。
示例:
假设要切分的文件为test.2012-08-16_17,大小1.2M,12081行。
1)
生成xaa,xab,xac三个文件。
wc -l 看到三个文件行数如下:
5000 xaa
5000 xab
2081 xac
2)
生成xaa,xab两个文件
ls -lh 看到 两个文件大小如下:
600K xaa
3)
得到三个文件,文件名的前缀都是example
ls -lh 看到文件信息如下:
500K exampleaa
500K exampleab
154K exampleac
awk '/^xx/ { print }' dict_uniq.txt > 07.txt
yum remove vmware-* -y rpm -e --noscripts vmware-open-vm-tools-xorg-drv-display.x86_64 rpm -e --noscripts vmware-open-vm-tools-xorg-drv-mouse.x86_64
Unable to create symbolic link "/usr/lib/vmware-tools/bin"
or
Unable to create symbolic link "/usr/lib/vmware-tools/libconf"
Seems the installer has a bug where it fails to remove the existing directory before creating the symlink (it prompts to overwrite, but of course overwriting a dir with a symlink is not possible - therefore I'd call this a BUG)
The solution is to simply remove the existing dirs:
rm -rf /usr/lib/vmware-tools/libconf
rm -rf /usr/lib/vmware-tools/bin
and run the install again:
./vmware-install.pl -d
位置 | 标志 | 含义 |
remote之前 | * | 响应的NTP服务器和最精确的服务器 |
+ | 响应这个查询请求的NTP服务器 | |
blank(空格) | 没有响应的NTP服务器 | |
列表上方 | remote | 响应这个请求的NTP服务器的名称 |
refid | NTP服务器使用的更高一级服务器的名称 | |
st | 正在响应请求的NTP服务器的级别 | |
when | 上一次成功请求之后到现在的秒数 | |
poll | 本地和远程服务器多少时间进行一次同步,单位秒, 在一开始运行NTP的时候这个poll值会比较小,服务器同步的频率大,可以尽快调整到正确的时间范围,之后poll值会逐渐增大,同步的频率也就会相应减小 | |
reach | 用来测试能否和服务器连接,是一个八进制值,每成功连接一次它的值就会增加 | |
delay | 从本地机发送同步要求到ntp服务器的往返时间 | |
offset | 主机通过NTP时钟同步与所同步时间源的时间偏移量,单位为毫秒,offset越接近于0,主机和ntp服务器的时间越接近 | |
jitter | 统计了在特定个连续的连接数里offset的分布情况。简单地说这个数值的绝对值越小,主机的时间就越精确 |
awk '/^root/ { print }' /etc/passwd 打印以root开头的行
简单来说netsh winsock reset命令含义是重置 Winsock 目录。如果一台机器上的Winsock协议配置有问题的话将会导致网络连接等问题,就需要用netsh winsock reset命令来重置Winsock目录借以恢复网络。
winsock是windows网络编程接口,从Windows XP SP2开始内置了一条命令使用netsh能够对该接口进行修复。
netsh是一个能够通过命令行操作几乎所有网络相关设置的接口。比如设置IP,DNS,网卡,无线网络等。
netsh winsock reset:
先进入netsh
然后进入winsock这个部件
对winsock这个部件执行reset命令。
效果就是重置Winsock。对于一些WinSock被破坏导致的问题有奇效。在netsh出现之前,对于WinSock问题的修复是非常繁琐的。
perl -ne 'print unless $a{$_}++' file > out put file
awk '{a[$1]} END {for(i in a) print i}' filename > out put file
sort myfile.txt | uniq > out put file
awk '!_[$0]++' file
ruby -00 -ne 'puts $_.split("\n").uniq' file
perl -ne 'print unless $a{$_}++' file
sed '$!N; /^\(.*\)\n\1$/!P; D'
UE可以处理几乎任意大小的文件,当你想阅读GB级别的LOG文件时,UE时很好的选择。
1.关闭行号显示
关闭行号显示可以让你更快的打开一个大型文件。
2.不使用临时文件
不使用临时文件可以减少加载大型文件的时间。你可以设置阈值来合理使用这个功能。
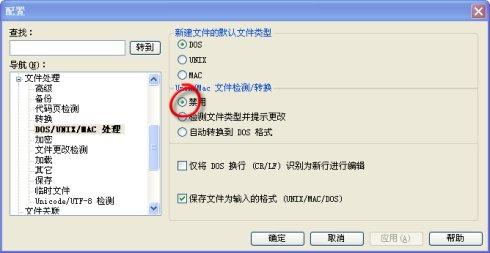
3.关闭文件检测和转换
最后,关闭文件检测和转换功能,就能快捷的打开大型文件了。
设置好以后,我们用一个4GB的文件来做测试。
这是我们要打开的文件:
用UE打开: