正则表达式的与或非
我们都知道,写正则表达式有点像搭积木,复杂的功能总可以拆分开来,由不同的元素(也就是子表达式)对应,再用合适的关系将它们组合起来,就可以完成。在这一节,我们讲解常见的与或非关系的表达。
与
“与”是最简单的关系,它表示若干个元素必须同时相继出现,比如匹配单词cat,其实就是要求字符c、字符a和字符t必须同时连续出现。
正则表达式表达“与”关系非常简单,直接连续写出相继出现的元素就可以,我们可以想象,在各个元素之间,存在看不见的连接操作符·,比如上面匹配单词cat的正则表达式,就是『cat』,我们可以将它想象为『c·a·t』。
“与”关系也不限于字符之间,任何子表达式都可以用它来连接,如果我们把上面单词中的a替换为字符组『[au]』,表达式就变为『c[au]t』,你可以想象为『c·[au]·t』。
或
“或”是正则表达式灵活性的重要体现,我们可以规定某个位置的文本的“多种可能”,比如要匹配cat或是cut,在正则表达式看来,就是“字符c,然后是a或u,然后是t”。
如果“或”的多种可能都是单个字符(一般要求ASCII字符,中文字符等多字节字符的情况,可以参考本书专门论述的章节,此处仅以ASCII字符为例),就可以用字符组来表达“或”的关系,比如上面的cat或者cut的情况,正则表达式写做『c[au]t』,其原理如下:
更复杂的情况是“或”的多种可能,并非都是单个字符,有些可能是多个字符。比如,我们可以看一个更复杂的例子,不仅要匹配cut,还要匹配c开头、t结尾的单词chart、conduct和court。也就是说,在开头的c,结尾的t之间“可能”出现的是:u或har或onduc或our。
遇到这种情况,就不应使用字符组,而应当使用多选分支『(…|…)』,将各个“可能选项”列在多选分支中。于是,正则表达式变为『c(u|har|onduc|our)t』,其原理如下: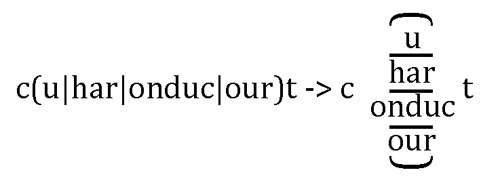
关于多选分支,还有两点要补充:
多选分支也可用于“每个选择都是单个字符”的情况,比如『c[au]t』写成『c(a|u)t』是没错的,但字符组的效率要远高于多选分支,所以,在这种情况下,推荐使用字符组『c[au]t』;
默认的多选分支『(…|…)』使用的括号是会捕获文本的,也就是说,括号内的表达式真正匹配成功的文本会记录下来,匹配完成之后可以提取出来,具体到上面的例子,就是我们有办法在匹配完成后“提取”出u或har或onduc或our。但许多时候,我们需要的只是整个表达式的匹配,而不关心“匹配时到底选择的哪种可能情况”,在这种情况下,我们稍加修改,使用“不捕获文本的括号”,可以提高效率。不捕获文本的写法也很简单,只是在开扩号之后加上字符『?:』,也就是『(?:…|…)』,具体到上面的例子,就应该写成『c(?:u|har|onduc|our)t』。这样做虽然繁琐点,但效率有保障,阅读起来也不困难,我推荐养成这种习惯,只要用到了括号,就想想是否真的要捕获括号内表达式匹配的文本,如果不需要,就是用不捕获文本的括号。
非
“非”看起来简单,其实是最复杂的,以下分几种情况讨论。
首先讨论针对字符的“非”:不容许出现某个或某几个字符。这是最简单的情况,直接用排除型字符组就可以对付,仍然用上面的例子,如果要匹配的单词是c开头、t结尾,中间有一个字符,但不能是u(也就是说,整个单词不能是cut),直接用『c[^u]t』就可以了,若中间的字符不能是a或u(也就是说,整个单词不能是cat或cut),则表达式改为『c[^au]t』。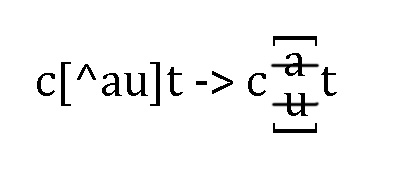
如果你认真读过关于排除型字符组的章节,肯定会知道,这个表达式能匹配的只是cot之类的单词,因为中间的排除型字符组『[^au]』必须匹配一个字符。可是,如果我们还想要匹配chart、conduct和court,怎么办?最简单的想法是去掉排除型字符组的长度限制,改成『c[^au]+t』——不幸的是,这样行不通,因为这个表达式的意思是:c和t之间,是由多于一个“除a或u之外的字符“构成的,而chart、conduct和court,都包含a或u。
我们回头仔细看看这个“非”的逻辑,我们发现,其实我们要否定的是“单个出现的a或u”,而不仅仅是“出现的a或u”,所以才出现这样的问题,要解决这个问题,就应当把意思准确表达出来,变成“在结尾的t之前,不容许只出现一个a或u”。想到这一步,我们就可以用否定顺序环视『(?!…)』来解决了,它表示“在这个位置向右,不容许出现子表达式能够匹配的文本,我们把子表达式规定为『[au]t\b』(最后的『\b』很重要,它出现在t之后,保证t是单词的结尾子母)。
有了这点限制,匹配a和t之间文本的表达式就随意很多了,我们可以用匹配单词字符的简记法『\w』表示,于是整个表达式就变成了『c(?![au]t\b)\w+t』。请注意,这里出现的并不是排除型字符组『[^au]』,而是普通的字符组『[au]』,因为否定顺序环视『(?!…)』本身已经表示了“否定”的功能。
如果我们再进一步,“整个匹配文本中都不能出现字符串cat”,要怎么办呢?许多人的思路就是借鉴处理“或”关系的思路:既然字符组对应单个字符的情况,多选分支对应多个字符的情况,那么在否定时也是这样。可惜,正则表达式并没有提供与多选分支对应的“否定”结构,那么,应该怎么办呢?
解决的办法还是得依靠否定顺序环视——“整个匹配文本中都不能出现字符串cat”,换句话说,就是“在文本中的任意位置,向右,都不能出现该字符串”。因此,我们用两个锚点『^』和『$』,分别匹配整个字符串的开头和结尾位置,再用否定顺序环视『(?!cat)』表达“不能出现字符串cat”。
即便知道了原理,也不见得能写对正则表达式,比如『^(?!cat).+$』就是不正确的,因为它只限定了在文本的开头(也就是『^』)右边不能出现cat,而我们真正要做的是,在文本的每一个位置右边,都不能出现cat,所以应该改成『^((?!cat).)+$』;但这还说不上完美,根据前面提到的关于括号捕获的知识,因为此处并不需要括号捕获的文本,所以最好使用非捕获型括号『(?:…)』,最终我们得到的表达式就是『^(?:(?!cat).)+$』。

